
- PMF(Positive Matrix Factorization) 모델은 수용 모델(Receptor model)의 한 종류로써 US EPA (Environmental Protection Agency)에서 권장하는 대기 모델링 중 하나이다.
- 수용모델은 수용체 또는 수용지역에서의 대기 오염물질 종류 및 농도 등의 데이터를 바탕으로 한 통계적 분석을 통하여 대기오염물질 배출원(Source)의 기여도를 정량화하기 위한 수학적 접근법이다.
- 수용 모델의 목표는 측정된 물질들의 농도와 배출원 정보 사이의 Chemical Mass Balance (CMB)를 요인의 수 p, 각 배출원의 오염물질 정보 f, 개별 샘플에 개별 요인이 기여하는 질량의 양 g (특정 배출원에 대한 배출량, 즉 측정기간에 대한 오염원의 강도 (strength))를 사용하여 계산하는 것이다.

- i : 샘플의 수, j : 오염물질 종류, x : i 개의 시료에서 측정된 j 개의 오염물질로 나타낸 데이터 행렬, e : 잔차(나머지) 행렬 (residual matrix)
- 모델의 최적화를 위한 Objective Function Q는 PMF의 중요한 매개변수로써 모델 내 반복 알고리즘을 통해 최소화된다.
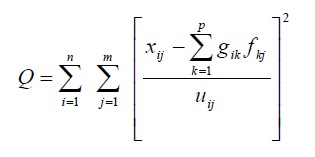
- u : 불확도 (uncertainty), 계산식의 분자는 잔차(나머지) e
- Q는 2가지 버전(true, robust)으로 모델 내에서 표시된다.
- Q (true) : 모든 포인트를 포함하여 계산된 값
- Q (robust) : 불확도로 수정된 잔차(나머지)가 4 이상인 샘플들을 제외한 후 계산된 값
- 불확도가 매우 커지면, 두 파라미터는 비슷한 값을 가지게 된다.
- 모든 샘플은 개별 불확도를 가져야 하며 이의 계산 방법은 여러 가지가 있으며, 연구자는 연구 방향에 맞는 최적의 계산 방법을 결정하여야한다.

- MDL (Method Detection Limit) : 방법검출한계
 |
| 미세먼지 데이터의 PMF 모델링 분석을 위한 불확도 계산 방법 리스트 |
- 위의 계산 방법들은 농도값이 MDL 보다 클 때 사용한다.
- 이상으로 US PMF 모델에 대한 간단한 소개와 함께 불확도 계산 방법에 대하여 알아보았다.
참고 문헌
- US EPA 메뉴얼
- https://m.blog.naver.com/PostView.nhn?blogId=chylook&logNo=70074232400&proxyReferer=https%3A%2F%2Fwww.google.com%2F,
- Adam R., Shelly I. E., and Prakash V. B., Receptor Modeling of Ambient Particulate Matter Data Using Positive Matrix Factorization: Review of Existing Methods, J. Air & Waste Manage. Assoc., 2007, 57:146-154
















































